Kleine Smart-City-Datenplattform für Testzwecke

Achtung! Ironie an: eine Smart City-Datenplattform sieht für viele Kommunen aus, wie die Öl-Plattform im Titelbild. Glänzend im Abendlicht, technisch, leider weit entfernt und sicherlich teuer. Ironie aus. In diesem Artikel erfahren Sie, wie eine schnell aufgebaute und preiswert betriebe Datenplattform für Testzwecke aussieht.
Digitale Zwillinge
Wer Smart City will, kommt um das Thema einer Datenplattform nicht herum. Das Aufzeichnen von Sensordaten, die Analyse von Beständen aus den Ämtern und die Steuerung von Vorgängen sind Grundvoraussetzungen für den technischen Betrieb und eine smarte Verwaltung. Vorteile werden versprochen von einer Verknüpfung der Bestandsdaten, um durch komplexe KI-Analysen Mehrwerte für die Bevölkerung zu schaffen. Viele Kommunen beschäftigen sich mit dem Thema Datenplattform intensiv. Die Städte Hamburg, Leipzig und München haben Datenplattformen in den letzten Jahren aufgebaut und sollen mit Förderung der Bundesregierung im Projekt „Connected Urban Twins“ wesentliche Fortschritte erzielen. Solche Datenplattformen verknüpfen dutzende von Quellsystemen und beinhalten Daten von tausenden von Sensoren (Quelle). Eine erste Übersicht findet sich hier.
Plädoyer für eine einfache Lösung
Aber muss man eine umfangreiche Datenplattform aufbauen, wenn man #einfachmalmachen will? Wir empfehlen einen Schnellstart mit Datenplattformen, um zu erfahren, wo die Vorteile liegen und welche Aspekte man beachten sollte. Denn nach wie vor steht die Anwendung im Vordergrund und die Datenplattform ist eigentlich „nur“ eine Querschnittaufgabe im Hintergrund.
Welche Vorteile bringt dieses Vorgehen:
- Der Aufbau einer Datenplattform dauert Zeit. Aber wieso warten müssen?
- Gerade bei Anwendungen im Feld werden neue Technologien eingesetzt (z.B. LoRa-WAN). Die Datenplattform ist hier nicht die wichtigste Frage, sondern Aspekte von Zuverlässigkeiten des Gesamtsystems, Stromverbrauch der Sensoren, Antennen und Reichweite, Standorte der Gateways. Dies sollte früh erprobt werden.
- Der Betrieb von innovativen Anwendungen erlebt häufig Änderungen des Systemaufbaus oder der Komponenten. Diese Änderungen müssen erprobt werden. Was bedeutet etwa das Auswechselns eines Sensors? Wie werden die Meta-Daten, z.B. der Standort oder die Seriennummer, erfasst, geändert und archiviert?
- Bereits früh im Projekt werden Daten verfügbar, die den Auftraggebern oder der Bevölkerung präsentiert werden können. Natürlich immer mit dem Hinweis, dass es sich um eine erste Systemversion handelt. Es wird aber greifbar, wie eine Lösung aussehen kann.
- Daten können gegenüber Erwartungen gespiegelt werden. Stimmt die Aktualität? Sind in den Daten Anomalien enthalten? Überraschungen sollten früh in einem Projekt kommen. Unsere Erfahrung ist, dass erst beim Umgang mit realen Daten wichtige Diskussionen im Team ausgelöst werden.
- Je länger Systeme im Betrieb sind, um so wahrscheinlicher treten Systemstörungen auf. Welchen Einfluss hat die Kälte im Winter auf die Lebenszeit einer Batterie? Müssen Regensensoren im Herbst von Laub befreit werden – und welche einfachen Gegenmaßnahmen erweisen ich als hilfreich? Solche Tests mit realem Charakter können während der Aufbauphase wesentliche Erkenntnisse für ein breites Ausrollen in der Fläche bringen.
Der Aufbau
Gut, wenn man bis hierhin übereinstimmt, stellt sich sofort die Frage, wie das gehen soll. Wir können hier nur einen kleinen Abriss des empfohlenen Vorgehens geben, gerne erfahren sie aber mehr in einem persönlichen Gespräch. Denn viel ist es wirklich nicht, um innerhalb eines Tages mit wenigen Euro Betriebskosten pro Monat eine Smart City-Datenplattform für Testzwecke zu erhalten. Wie das geht, zeigen wir hier exemplarisch für ein System aus einigen Sensoren, die über eine Stadt verstreut Daten erfassen. Die Datenübertragung nutzt den Standard LoRa-WAN.
Was benötigt man denn?
- Sensoren mit LoRa-WAN.
- Zugang zu TheThingsNetwork (TTN), für den Anfang reicht die Community-Edition aus. Die Sensordaten werden hier zusammengeführt.
- Eine Instanz eines ioBrokers sammelt die Zustände der Daten auf. Auf diesen Daten kann dann gerechnet werden und eventuell Steuerbefehle abgesetzt werden.
- In einer influxDB werden Zeitreihen, also der Verlauf eines Sensorwertes über die Zeit, aufgezeichnet und bei der Abfrage auf relevante Zeiträume verdichtet.
- Mittels Grafana werden die Daten angezeigt.
Bei allen Lösungen handelt es sich um frei verfügbare offene Software-Lösungen. Also erst mal werden keine Lizenzkosten im Projekt anfallen.
Die Aufgaben verteilen sich dabei wie folgt:
- Man registriert einen Nutzer bei TTN.
- Die eigenen Sensoren werden dann in TTN registriert. Sie können sofort über jedes Gateway von TTN empfangen werden und die Live-Daten können ausgewertet werden. Nach einem Test können die Sensoren in der Fläche montiert werden.
- Eventuell können, sofern durch vorhandene Gateways die Funksignale der Sensoren nicht empfangen werden können, eigene Gateway installiert werden. Auch diese werden in TTN registriert.
- In TTN wird eine Weiterleitung der Daten, etwa mit MQTTzum ioBroker eingerichtet. Es wird empfohlen, alle Datenbereinigungen (z.B. Löschen von Ausreissern), Berechnungen (z.B. Tiefstwert des laufenden Tages) auf der ioBroker-Instanz mittels Skripten durchzuführen.
- Die automatische Sicherung von Daten in der influxDB geschieht über den Adapter des ioBroker. Nur markierte Werte werden an die Datenbank übertragen.
- In der influxDB wird die Behandlung der historischen Werte definiert, also z.B. wie lange die Daten vorgehalten werden und wie Zeitreihen verdichtet werden. Verlaufsdaten, die sich sehr schnell ändern werden nach Monaten in der Datenbank zum Beipsiel auf charakteristische Werte wie Tageshoch-/-tiefwerte, Durchschnitt und mittlerer Wert umgerechnet und nur diese werden langfristig gespeichert.
- In Grafana werden die influxDB und der ioBroker als Quellen angelegt, wo sie dann in Dashboards für Grafiken und Zustandsanzeigen genutzt werden können.
Die nachfolgende Grafik erläutert dieses Schema.
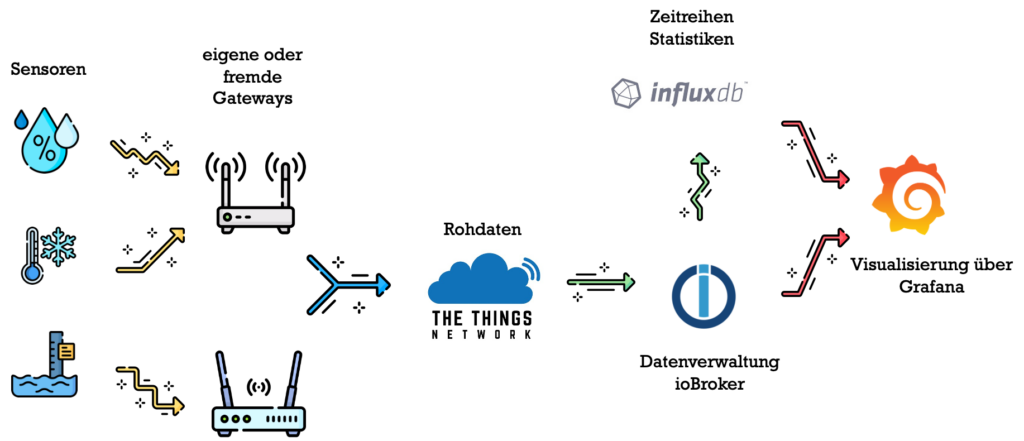
Die Sensoren, links dargestellt, erfassen die Messwerte und senden diese per LoRa-WAN-Protokoll (gelbe Pfeile) an die Gateways. Hier werden die Daten an das TTN weitergeleitet (blaue Pfeile). Sofort werden die Daten nach Umrechnung der Nutzdaten an den ioBroker weitergeleitet und auch in der influxDB historisiert (grüne Pfeile). Auf dieser Ebene findet die eigentliche Datenverarbeitung statt. Für die Anfrage fragt Grafana die Daten ab (rote Pfeile).
Das ist nicht „quick & dirty“, sondern nur schnell
Bei den Bausteinen TheThingsNetwork, influxDB und Grafana handelt es um den jeweiligen Standard im Aufgabengebiet. Das Risiko eines Einsatzes ist also begrenzt, die Systeme laufen in großer Anzahl, es besteht genügend Expertise, die sich in Foren und eventuell gegen Bezahlung schnell finden lässt.
Bleibt nur noch der ioBroker. Mit mehr als 75.000 Installationen weltweit (Quelle) und mehreren Jahren Entwicklung ist das meist auf Linux betriebene System ausgereift. Der aus unserer Sicht entscheidende Vorteil liegt in einer aktiven Community, welche über 400 Adaptoren zur Verfügung stellt, die den ioBroker mit einer Vielzahl technischer Plattformen und Geräte verbindet. Hierbei sind auch zahlreiche Lösungen, die sich in kommunalen Gebäuden finden lassen, wie etwa komplexe Heizungssteuerungen oder Gebäudeautomation (z.B. KNX). Allgemeine Adaptoren, wie SNMP, UPnP, JSON, ermöglichen das einfache Einbinden von Datenquellen mit sehr gut bekannten Formaten. Datenpunkte könne nicht nur gelesen, sondern auch in durch Adaptoren angebundene Systeme geschrieben werden, so dass komplexe Steuerungsaufnahmen realisiert werden können. So ist es sehr einfach, per Skript die Raumtemperatur zu ändern. ioBroker verfügt über eine Skriptverwaltung, die neben Javascript auch Node-RED und Blockly zulässt. Wartung, Pflege und Monitoring des Systems sind einfach zu handhaben.
Für die Datensammlung werden die Systeme über Standardprotokolle verbunden, wobei mehrere zur Auswahl stehen. Wir haben ganz gute Erfahrungen mit MQTT gemacht. Diese sind bei TTN und ioBroker mit an Bord und leicht konfiguriert. Der ioBroker hat einen eigenen Adapter für influxDB, es kann pro Datenpunkt ausgewählt werden, ob und in welcher Datenbank er gespeichert werden soll.
Der Betrieb kann in der Cloud stattfinden, oder als Testsystem auch auf einem NAS (Network Attached Storage). Es ist also keine Serverfarm notwendig. Ein bisschen technisches Verständnis ist notwendig, aber im Grunde handelt es sich nicht um eine Hexerei. Hört sich das zu einfach an? Für einen realen Betrieb in einer Stadt sicherlich ja. Aber die Aufgabe war eine andere: schnell ein System zur Verfügung stellen, welches mehr als nur Spielzeug und Messe-Prototyp ist, um früh im Projekt Erfahrungen mit neuen grundlegenden Technologien zu erlauben, die dann in das Projekt noch einfliessen können. So werden durch #einfachmalmachen teuere Fehlentscheidungen vermieden.
Zum Schluß noch ein wichtiger Hinweis: der vorgeschlagene Aufbau ist ein Testsystem und konzentriert sich auf das Erfassen verteilter Daten. Verknüpfungen von Geoportalen wird hier ebenso wenig spaßig sein wie das Verschneiden komplexer Daten aus dem Sozialamt. Dies sind auch komplexe Aufgaben, aber doch in der Regel besser verstanden als ein verteiltes System mit neuen Technologien.